

图文识别有多强?从扫描文件到识别广告
人的眼睛常被誉为“心灵的窗户”,通过眼睛,我们观赏风景、观察事物、读懂意义、体味情感;
而对于机器来说,若想让TA的“眼睛”比人类看得更快、更细、更准,甚至更“懂”,则需要付出更多的努力——
不久前,在第24届国际模式识别大会(ICPR 2018)举办的MTWI图文识别挑战赛中,科大讯飞与中科大语音及语言国家工程实验室(NELSLIP)联手,一举包揽全部三项任务的冠军,让机器的“眼睛”在识别、定位、分析的三部曲里演绎出了精彩的乐章。

从智能语音到图像识别,科大讯飞在人工智能领域的核心技术源头不断突破、游刃有余。此次比赛包揽冠军的奥秘在何处?与讯飞此前的不断积累与探索有什么联系?纵观现在、展望未来,图文识别是否已经走进我们的生活、未来又会有怎样的发展前景?
图文识别有多强?从扫描文件到识别广告
提起图文识别,就不得不提起TA——OCR。OCR(Optical Character Recognition),最早是指通过电子设备(如扫描仪等)获取文件中字符的图像(扫描或拍照),随后通过检测图像中暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机可识别字符的过程。

常见的扫描仪,你的办公桌上是不是也有它?
随着技术与社会的发展,现在的OCR已经不再局限于最初识别扫描文件字符和手写字符,而是拓展出了更多的适用环境、场景和形式。简单来说,就是“拍一拍,图片变文字”。因此,对OCR的考验就需要在不同适用场景下做可靠性测试,不断用不同数据集对模型和算法进行验证,进而追求更可靠、适应场景更广泛的OCR技术和模型。
本次MTWI(Multi-Type Web Images,多样式网络图像)挑战赛作为ICPR首次进入中国内地后所举办的比赛,不仅切合了上述需求,更是接了一把地气——比赛使用的数据集来自于阿里巴巴收集和标注互联网电商宣传图片。

没错,就是你“剁手”时看过的图!
比赛中,每支参赛队伍在这些图像里要完成三个任务:
01
文本行识别:识别出给定文本行图像中的文字

02
文本检测:在给定图像中检测出文本行所在的位置

03
端到端文本检测和识别:对给出图像进行文本行识别和文本检测,输出识别结果

简而言之就是:
图片中的这里写了什么?
在这张图中,哪里出现了字?
这张图片里有什么字?
来自电商的广告图片给参赛队伍带来了不少难题,首先,这些图像字体变化多样、字号大小差异很大,位置排布不规律,图像里还有很多干扰背景,让字符分割和序列建模变得异常复杂、困难;其次,比赛的数据集中包含有很多相比英文字符结构更加复杂的汉字,根据统计发现,有75%的汉字出现不到50次,这对于训练模型提出了更苛刻的要求。
打开夺冠大门的金钥匙:借鉴变通、精准全面
迎难而上总是乐趣无穷,这次比赛吸引了三星中国研究院、商汤科技、网易、清华大学、北京大学、中科院等众多著名研究机构参与。强手如林,科大讯飞与NELSLIP能够脱颖而出必有法宝,科大讯飞AI研究院的小伙伴揭秘了背后的诀窍。
在语音识别技术和自然语言理解技术领域所使用的序列建模和神经网络中的注意力机制,成为OCR技术“灵感的缪斯”——在借鉴的基础上,科大讯飞联合NELSLIP团队基于Encoder-Decoder模型构建了包含深度神经网络的图文识别系统并提出了新的无切分结构分析算法。
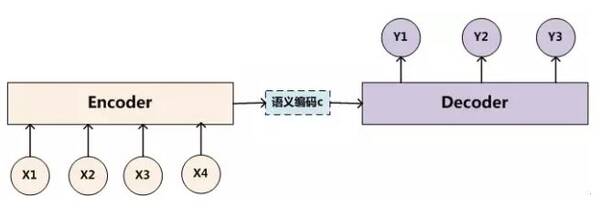
Encoder-Decoder模型
传统Encoder-Decoder模型是一个序列建模的通用处理模型。对于一对数据X,Y来说,我们输入给定的X,通过Encoder-Decoder框架来生成目标数值Y。但是这样的模型在字符识别的环境中就遇到局限,即只能识别出给定数据集中的字符,对于数据集之外的字符就无能为力了。
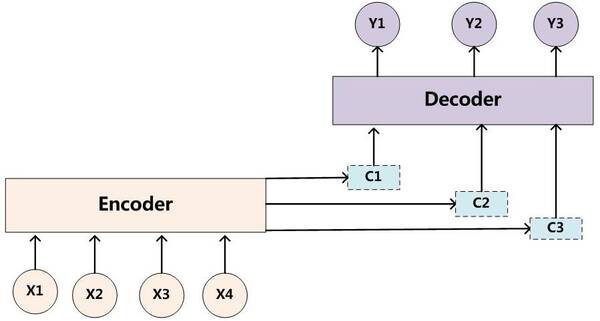
引入注意力机制后的Encoder-Decoder模型
现在科大讯飞与NELSLIP的联合团队通过引入注意力(Attention)机制,在识别出字符的多个部件后再利用动态规划策略进行重组,从而实现通过字符部件来识别训练集之外的字符。这种依赖分析结构的方法,不仅大幅扩展了识别的范围,还有效地解决了在部分场景中识别效率底下的问题。
例如训练集中若只有两个已标注样本(label),“二”和“天”,那么按照原有模型仅能识别出“二”和“天”;而通过对字符部件进行建模,可以从中提取部件“一”和“人”,这样除了可以识别“二”、“天”之外,还可以进一步识别出“一”、“三”、“人”、“大”等由“一”和“人”这两个部件所构成的字符。
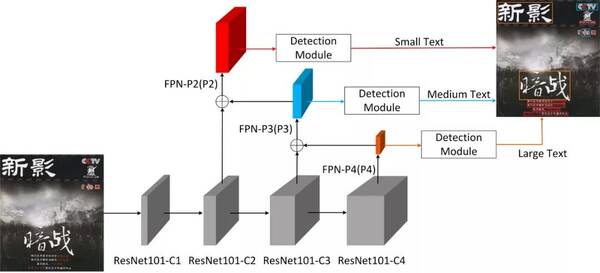
而在文本行检测任务中,科大讯飞又与NELSLIP基于目标检测中的多尺度测试构建空间金字塔,在各个尺度上预测矩形框(如下图所示);
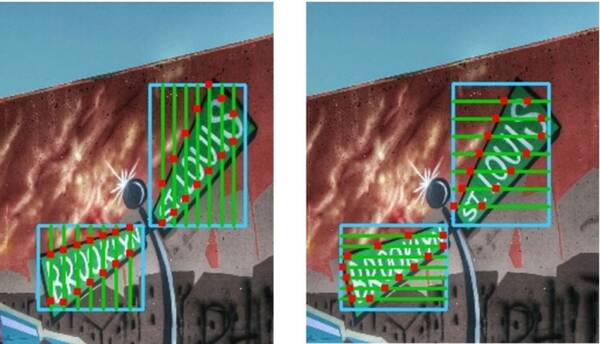
然后通过在矩形框内回归滑动线点(如下图中的红点)得到各种朝向文本行的顶点,从而解决文字尺度变化大、文本行朝向不统一的问题,完成文本行的精确定位。
让“神话”走进现实:应用广达、未来可期
在ICPR 2018 MTWI图文识别挑战赛中熠熠生辉的这些巧思与磨砺,其实已经走入现实,在各类应用中触达你我:
不知道各位是否还记得我们在多年前的一篇推送:
阅卷机器人:你的考卷,我来打分
当时我们向大家介绍了智能阅卷中所应用的自然语言处理技术。事实上就阅卷而言,如果说给出分数是阅卷流程的终点,那么让机器看到学生的回答就是分数的第一位数字,如果阅卷系统难以识别和获取学生的答案,一切阅卷过程就都将无从谈起。
在两年前可能还只是“小试牛刀”的智能机器阅卷技术,如今已经大规模投入实际使用,不仅可以实现作文、翻译、问答等主观题自动评分,还能帮助考试主管部门自动检测空白卷、相似卷、内容抄袭等异常试卷,从而在提高阅卷质量的同时,大幅减少阅卷的人员投入,促进各类考试更加公平、公正。
不过OCR的适用范围绝不仅仅于此,可以说只要是任意有图像有字符的地方,科大讯飞的图文识别技术就可以出发挥它的价值。
或许阅卷离我们的日常生活有点远,如果想要更便捷地体验OCR技术,打开讯飞输入法、讯飞有声等APP,就可以直接试试图片转文字的效果了。如果你手中还有讯飞翻译机2.0,点击拍照翻译,不仅可以感受到OCR的方便,更能够感受到多重AI技术融合后的美好体验。
讯飞输入法AI拍照输入
讯飞有声拍照朗读功能
技术的进步常比想象中走得更快,在投入语音识别技术的时候,很少有人能想到语音识别技术的逻辑和方式能够被同为模式识别分支的字符识别所借鉴;在开始起步研究识别扫描文件中字符的时候,也很少有人预见到这么快就已经可以在随机场景图像中识别字符。
放眼未来,在学术界和产业界大量投入以及后续机器翻译和自然语言理解等技术的协作优化下,“能听会说”的机器走到我们面前的那一天已经指日可待,而“能理解会思考”的机器想必也不再遥远。
从考量肺结节检测的国际医学影像领域权威评测LUNA,到目前公认自动驾驶领域内最具权威性、专业性的图像语义分割评测集Cityscapes,到医学影像领域的国际顶级会议ISBI举办的糖尿病视网膜病变分割与分级挑战赛(IDRiD),再到如今ICPR 2018 MTWI挑战赛,科大讯飞“转战”计算机视觉领域虽时日不长,却已处处开花。
技术的互通有无、举一反三,加之不同研究领域长期坚持所积累的海量数据,浇灌出多项国际权威赛事的耀眼成绩;但绽放的花朵只有化为累累的硕果,才能真正赋能社会、人类。
“让机器能听会说,能理解会思考”是科大讯飞一直追求的目标。目前通过在语音识别、语音合成和图文识别等感知智能领域的积累,一个拥有感知能力的强大机器已经初露锋芒;未来通过讯飞开放平台引入认知智能技术,必将使各项AI能力更好地改变人机互动模式,让更生动和有趣的应用充满我们的生活。

